I am proud to share that I am now an OCI Generative AI Certified Professional! The certification process was an incredibly enriching experience, offering deep insights into various topics, including large language models (LLMs), the OCI Generative AI service, essential building blocks for LLM applications, and the practical experience of creating an LLM app using OCI’s generative AI service. In this blog post, “Exploring LLMs and OCI Generative AI”, I’ve captured the key learnings and insights I gained during the certification process.
LLM
A language model is a probabilistic model of text. We can better explain this with an example.
I stay at Bangalore, and I contacted a travel agent to check for the nearest hilly region. The travel agent replied as ________________
Nandi hills, Kudremukh, Kumaraparvath, Mullayanagiri, Brahmagiri
Consider the word probability for each of the above as 0.3 ,0.2 , 0.1 , 0.1 , 0.2 respectively.
The language model knows about a set of words called vocabulary and it gives a probability to every word in its vocabulary of appearing in the blank. The LLM is no different from LM, the Large in the “large language model” refers to the number of parameters and there are no agreed-upon threshold upon which a model becomes large.
LLM Architecture
Here the focus is on two architecture models for LMs that are as follows:
- Encoders : Encoder models embed text, converting a sequence of words into an embedding. (vector/s or numerical representation). Example: BERT
- Decoders : Decoder models decode or generate text. Decoder models take a sequence of tokens and outputs next token. Decoder models tend to be pretty large compared to relatively small encoder models. Example: Llama2, GPT3, GPT4
LLM prompts
The simplest way to affect the distribution over the vocabulary is to change the prompt. A prompt is the text we provide to an LLM as input, which may include instructions and/or examples. Prompt engineering is the process of iteratively refining a prompt to elicit a particular style of response.
Some of the prominent prompting strategies are least to most, step back, chain of thought. However, we need to note certain issues associated with prompting, such as prompt injection/jailbreaking and memorization.
Another way to significantly affect the distribution over vocabulary is training. Prompting is simply changing the input to LLM. Since we keep the model parameters fixed, prompting alone limits the model’s distribution over words. Using prompting alone may be inappropriate when we have training data or need domain adaptation. In training, we are changing the parameters to the model. There are many ways to train a model or change parameters to a model. We can reuse the same cluster to fine-tune several models.
Training or LLM fine-tuning techniques
- Fine-tuning (FT) – Take a pre-trained model and a labeled dataset. Change all the parameters of the model for a task.
- Parameter efficient FT – Less expensive. Isolate a few parameters for training or add a set of new parameters to the model.
- Soft prompting – Add parameters to the prompt to force it to perform specific tasks during training.
- Continual Pre-training – Similar to FT but does not require labelled datasets. Continually training the model to predict the next word is done here. This is useful to adjust to new domain.
Decoding
This is nothing but taking the distributions and generating text. In other words, this is the process of generating text with an LLM. Decoding happens iteratively 1 word at a time. At each stage of decoding, we use the distribution over vocabulary and select one word to emit. The word is appended to the input and the decoding process continues.
Greedy decoding and non-deterministic decoding are the two types.
Greedy decoding is picking the word in the vocabulary with the highest probability. In non-deterministic decoding, randomly picking the high probability candidates is done. Accordingly, the next set of words vary based on the earlier choice and the probability score also changes.
For the below earlier example, greedy decoding will yield Nandi hills, whereas non-deterministic decoding may yield any random choice that can be even Kumaraparath.
I stay in Bangalore and I contacted a travel agent to check for the nearest hilly region. The travel agent replied as ________________
Nandi hills, Kudremukh, Kumaraparvath, Mullayanagiri, Brahmagiri Word probability for each of the above are 0.3 ,0.2 , 0.1 , 0.1 , 0.2 respectively.
When using the non-deterministic decoding there is an important LLM parameter to know about, which is the temperature parameter. This parameter modulates the distribution over vocabulary and hence the output of LLM also varies accordingly.
Considering the above example, if temperature is increased the distribution is flattened over all the words and the probability of each words appears closer to each other. In case the temperature is decreased, the distribution is more peaked around the most likely word which is Nandi hills ,hence deviates more towards greedy decoding.
Hallucination
It refers to LLM generated text that is non-factual and/or ungrounded. There are some methods that are claimed to reduce hallucination (RAG). However, there is no known method to reliably keep LLM from hallucinating.
Grounding
It refers to generated text by LLM that is grounded in a document if the document supports the text generated. The research community has embraced attribution/grounding.
LLM Applications
A few applications of LLM include:
- RAG – This is primarily used in QA where the model has access to (retrieved) support documents for a query. User input would be a question. A question transformed into query is used to search a database for a corpus of documents. Retrieved documents and questions are provided as input to LLM and the model will generate a correct answer. The model is non-parametric,i.,e the same model can be used to answer any question about any corpus.
- Code Models – In code models, training is done on code, comments, and documentation instead of written language. This has been largely successful since 85% of people feel using models like co-pilot more productive. Code completion might be easier than text completion, given the fact that code is more structured, repetitive and less ambiguous than natural language. However, it has a narrow scope since writing code from scratch is fine but debugging success rate is less than 15 percent.
- Multi-modal and language agents – These models are trained on multiple modalities, i.e, texts, images and audio. In case of diffusion model, LLMs generate one word at a time to form a text. However, diffusion models generate images all at once rather than 1 pixel at a time. Image is a fixed size with fixed pixels but generating words is not fixed. Language agent models are more suitable for sequential decision-making scenarios. Examples: Playing chess, browsing the web in search of an item, operating a software autonomously.
OCI Generative AI Service
It is a fully managed service that provides a set of customizable LLMs available via a single API to build generative AI applications. Some of the high performing pretrained foundational models provided here are from cohere and meta. This service also provides flexible fine tuning, i.e, create custom models by fine tuning foundational models with your own data set. Lastly, it provides dedicated AI clusters that can host your fine tuning and inference workloads.
How does Gen AI service work

Generative AI is built to understand, generate and process human language at a massive scale. Use cases are text generation, summarization, data extraction, classification and conversation.
Some of the pre-trained foundational models available in OCI are
- Generation – Generate text instruction following models (cohere:Command & Command-light, meta:llama 2-70b-chat)
- Summarization – Summarize text with your instructed format , length and tone (cohere:command)
- Embedding – Convert text to vector embeddings semantic search. Search in many languages and across languages (cohere multilingual models)
Fine tuning
A key feature of OCI generative service is to fine tune the foundational models on a smaller domain specific dataset. This specifically improves model performance of specific tasks and improves model efficiency. OCI uses the T-few fine tuning ,i.e, the parameter efficient fine-tuning technique to enable fast and efficient customizations.
Dedicated AI clusters
These dedicated AI clusters are GPU-based compute resources that host the customer’s fine-tuning and inference workloads. Generative AI service establishes a dedicated AI cluster which includes a specific pool of GPUs and a dedicated RDMA cluster network for connecting the GPUs.
OCI console
Once you login to the OCI console and navigate to Analytics & AI > Generative AI, you will reach the OCI generative AI dashboard. Some of the important sections on the dashboard include the Playground, Dedicated AI clusters, Custom models and Endpoints. Clicking on the Playground will bring up the below screen.
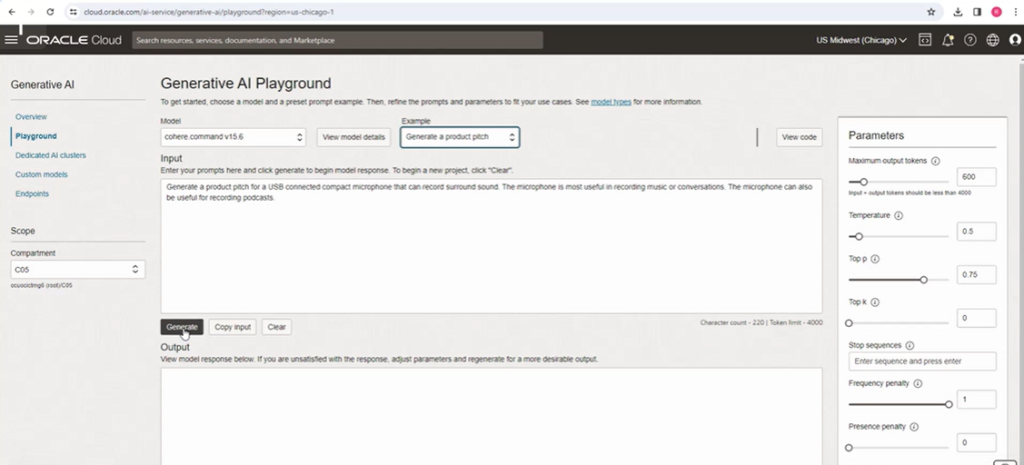
The model drop down option will show all the pretrained foundational models ,i.e, the Generation, Summarization and Embedding models available. For example, when you choose an input(model) and an example, then press the generate button, the system generates a text output because the generation foundation model was selected.
If you are not satisfied with the output you can go ahead and change the parameters on the right side of the screen. One of the main parameters to adjust is the temperature that will make the output more creative with the increase in value. Also you can check the output selecting different models from the drop down. Finally, when you are satisfied with the output, click on view code that will display the code for the generated output in Java and python. You can copy this code and integrate it into your own application.
One main point to note w.r.t OCI generative AI service is that it is currently hosted only in the Chicago, Frankfurt and London regions that one need to subscribe to inorder to use the service.
Before starting with the different model types, let us understand about tokens. Language models understand tokens rather than characters. The number of tokens depends upon the complexity of text. Simple texts 1 token/word. Complex texts 2 or 3 tokens/word.
Example : Friend 1token, Friendship 2 tokens (Friend and ship)
Generation models
- Cohere – Command : Model parameters(52B), context window(4096 tokens – sum of i/p & o/p)
- Cohere – Command-light : A smaller and faster version of command model. Model parameters(6B), context window(4096 tokens)
- Llama-2-70b-chat Model parameters(70B), context window(4096 tokens)
The parameters in the above models are as follows:
- Max output tokens – Max number of tokens model generates per response. OCI 4000 tokens.
- Temperature – This controls how creative the model should be. In other words, temperature is a parameter that controls the randomness of LLM Output. A temperature value of zero makes it more deterministic, i.e, limits the model to use the word with the highest probability, whereas an increased value flattens the distribution over all words.
- Top p, Top k – Two additional ways to pick the output token besides temperature. Selects from top k items probability(top k) or top tokens based on sum of their probabilities with p value being the reference(top p).
- Stop sequence – It is a string that tells the model to stop generating more content that can control the model output. Ex: a period(.)
- Presence/Frequency penalty – Assigns a penalty when a token appears frequently. This helps to get rid of repetition in your outputs.
- Show likelihood – Determines how likely it would be for a token to follow the current generated token. Every time a new token is generated, a number between -15 to 0 is assigned to all tokens. Tokens with higher value are more likely to follow the current token.
Summarization models
- Command Model from cohere – Generates a succinct version of the original text that relays the most important information. This is the same model used for text generation, but the parameters are different here.
This model has separate set of parameters as follows:
- Temperature – Same as for the text generation model. The value can vary from 1 to 5.
- Length – This indicates the approx length of summary. Choose from short, medium, long.
- Format – Whether to display the summary in a free form paragraph or in bullet points.
- Extrativeness – How much to reuse the input in the summary? Paraphrase(low) to verbatism reuse(high).
Embedding models
Embeddings are numerical representations of a piece of text converted to number sequence. Embeddings make it easy for computers to understand the relationships between pieces of text.
Word embeddings that are numerically similar are also semantically similar (meaning) ,i.e, for example monkey and gorilla will be more numerically similar than monkey and a lion. Likewise, similar sentences are assigned to similar vectors, different sentences are assigned to different vectors.
- Cohere embed-english-v3.0 , embed-multilingual-v3.0 – As the name suggests, the models support english and multilingual languages. The model creates a 1024 dimensional vector for each embedding. Hence, every embedding, whether it is a sentence, phrase or a paragraph get converted into the 1024-dimensional vector. And the model takes a maximum of 512 tokens per embedding.
- Cohere embed-english-light-v3.0, embed-multilingual-light-v3.0 – This is a smaller and faster version of the above model. This model creates a 384-dimensional vector for each embedding and takes a maximum of 512 tokens per embedding.
- Cohere embed-english-v2.0 – Previous generation model that creates a 1024-dimensional vector for each embedding and maximum of 512 tokens per embedding.
Prompt Engineering
Prompt is the input or initial text provided to the model. Meanwhile, prompt engineering is the process of iteratively refining a prompt for the purpose of eliciting a particular style of response.
- Completion LLMs – They use a large dataset of internet text to predict the next word, rather than to safely perform the specific language task the user wants.
- Fine-tuned LLMs – We use Reinforcement Learning with Human Feedback (RLHF) on a fine-tuned model to better align its behavior with human preferences and instructions.
Prompting types
- In context learning – conditioning an LLM with instructions and or demonstrations of the task it is meant to complete.
- k-shot prompting – explicitly providing k examples of the intended task in the prompt. Few shot prompting is widely believed to improve results over 0-shot prompting.
Advanced prompting strategies
- Chain of thought – provide examples in a prompt to show responses that include a reasoning step.
- Zero thought chain of thought – apply chain of thought prompt without providing examples.
Training LLMs from scratch would be demanding in terms of cost, data and expertise that would not be a good idea. So the next best idea would be to customize. The following methods can be used to customize your model.
- Incontext learning/Few shot prompting – User provides demo in the prompt to perform certain tasks. Popular techniques include chain of thought prompting. Limitation is the model processing context length is 4096 or smaller.
- Fine tuning – Improve model performance on specific tasks. Better than prompt engineering. Improve model efficiency.
- Retrieval Augmented Generation – Language model is able to query enterprise knowledge bases to provide a grounded response. RAGs do not require fine-tuning.
In Machine learning, inference refers to the process of using a trained ML model to make predictions or decisions based on new input data. However, in case of LLMs, inference refers to the model receiving new text as input and generating output text based on what it has learnt during training and finetuning.
Dedicated AI cluster sizing and pricing
To create a dedicated AI cluster to fine tune a cohere.command model, you need two large cohere units. However, to host this fine-tuned model, you need a minimum of one large cohere unit. As a result you need a total of three large cohere units. Fine tuning a model requires more GPUs than hosting a model (therefore 2 units used above). We can reuse the same cluster to fine-tune several models.
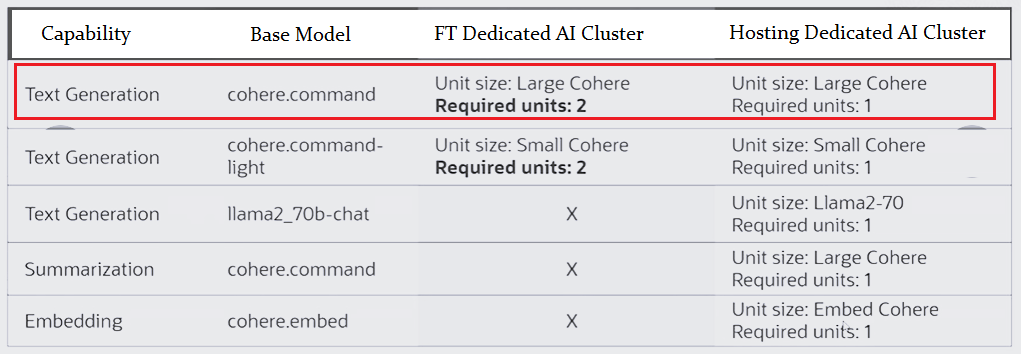
A person X wants to fine tune a cohere command model and after fine tuning, host the custom models. The steps involved will be as follows:
- Fine tuning a cohere command model would require two large cohere units.
- Let us consider that the fine-tuning job takes 5 hours to complete.
- One more consideration is that the fine tuning is done every week with the availability of new data.
- Finally, the fine-tuned model will be hosted and would require one large cohere unit.
Calculations:
- Minimum commitment that the service enforces would be, hosting 744-unit hours/cluster, fine tuning 1 unit hour/fine tuning job.
- Unit hours for each fine tuning, 2 units * 5hrs /week = 10-unit hours.
- Fine tuning cost/month would be 10-unit hours/week * 4wks = 40 * large cohere dedicated unit per hour price.
- Hosting cost would be 744-unit hours * large cohere dedicated unit per hour price.
- Total cost = (40+744) *large cohere dedicated unit per hour price.
OCI Generative AI Security
Customer data and model isolation ensure that access to customer data is restricted within the customer’s tenancy, preventing one customer from seeing another’s data.
OCI security services
- Leverages OCI IAM for authentication and authorization.
- OCI Key management stores base model keys securely.
- We store the fine-tuned customer model weights in OCI Object Storage buckets, where they are encrypted by default, and the keys are managed by the Key Management service.
Building blocks for an LLM Application
One limitation of standard LLMs is that they rely on the knowledge they were trained on, which may become outdated.
Retrieval Augmented Generation (RAG)
RAG addresses this by retrieving up to date information from external sources, thus enhancing the accuracy and relevance of the information it provides.
RAG consists of the following three components.
- Retriever – This component is responsible for sourcing relevant information from a large corpus or database.
- Ranker – This component’s primary role is to evaluate and prioritize the information retrieved by the retrieval system.
- Generator – This is a language model whose job is to generate factually correct and accurate human like text based on the input it receives.
RAG can be implemented using either of the following two methods.
- Sequence model – It considers all the documents together to generate a single cohesive response.
- Token model – Here, the system constructs the response incrementally, with each part reflecting information from the retrieved documents specific to that section.
Now, let’s explore the basic RAG pipeline used in natural language processing. The RAG architecture combines a retrieval-based component with a generative model to enhance the generation of text.
- Ingestion – The system ingests documents and indexes embeddings in a database for quick retrieval.
- Retrieval – System uses the input query to search through indexed data to find relevant information.
- Generation – From the top k results, system generates response based on the information retrieved.
Practical Application of RAG
Inorder to explore practical application of RAG, we will look into a question-answer-based chatbot session. The process unfolds as follows:
- Initial prompt
- In addition to the initial prompt, the model considers the entire chat history.
- We then combine the prompt and chat history to form what we call an enhanced prompt.
- We pass the enhanced prompt through an embedding model, which transforms the text into a mathematical vector (captures semantic meaning).
- The model finds the most relevant information to a query by performing an embedding similarity search. Here, the vector of our enhanced prompt is compared against a database of other vectors.
- The system retrieves document/s associated with the matching vector ID.
- Augment the initial prompt with the retrieved documents.
- The augmented prompt is fed to an LLM. The LLM combines the context of the conversation with specific retrieved information to produce responses that are precise and reliable.
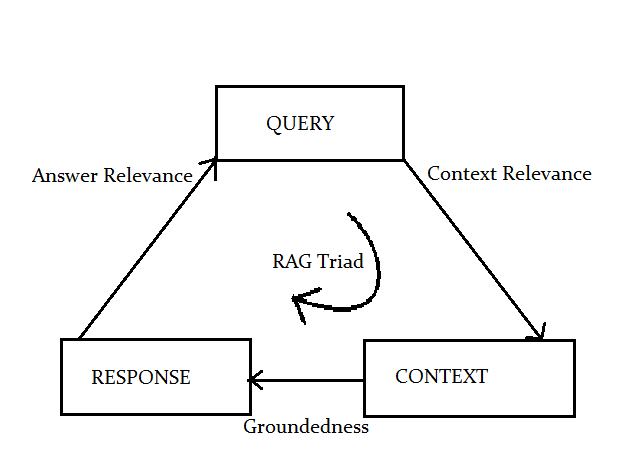
RAG triad is helpful to reduce the risk of hallucination.
- Context relevance – How well the RAG responses are aligned with the context of the conversation.
- Groundedness – Chatbot’s ability to provide responses that are accurate and based on reliable info.
- Answer relevance – Provide responses that are not only contextually appropriate but also specifically answer the user’s questions.
Vector databases
LLMs with RAG augment the process by using an external database, which is a vector database. Here we learn about how that vectors and vector databases improve the user experience.
Some of the most important features that makes the vectors databases so desirable with LLMs are as follows:
- Accuracy – stores data semantic relationship too that traditional database may not capture.
- Latency – Optimized for quick retrieval of high dimensional data.
- Scalability – Traditional database struggles with the sheer volume and high dimensional nature. Vector databases are adept at handling high volume and high dimensional data.
Vector databases are a core component of RAG-based LLMs. They use a type of database optimized for storing and querying vectors instead of a traditional rule-based.
- LLMs without RAG – It relies on internal knowledge learnt during pretraining on a large corpus of text. It may or may not use fine tuning.
- LLMs with RAG – LLMs with RAG use an external database which is Vector database. This extends the capabilities of LLMs to what they have been trained on.
Nearest Vectors and Advantages
Deep learning embedding models generate vectors that represent the semantic content of data, rather than the underlying words or pixels. These vectors efficiently compute similarity between items.
Unlike relational database, vector databases are optimized for multi-dimensional spaces, where the relationship between data points is not linear or tabular but is instead based on distances and similarities in a high-dimensional vector space.
As an example, let’s consider three groups of words based on similarities, i.e, fruits, animals and birds. If a user inputs peacock, it is closest to the bird group. To calculate the distance, we commonly use dot product and cosine distance to evaluate how similar or different two text embeddings are. When you provide a query or word, we will calculate the nearest vectors.
- KNN – You can use the K-Nearest Neighbors algorithm to perform a vector or semantic search and find the nearest vectors in embedding space to a query vector.
- ANN – Approx Nearest neighbor algorithms are designed to find near optimal neighbors much faster than exact KNN searches, but accuracy is lower than KNN.
Some of the most used vector databases are , Chroma, Oracle AI vector search, Weaviate, Pinecone, Faiss.
Lastly, the following list provides clarity on the advantages of Vector databases usage with LLMs.
- Addresses the hallucination (factually incorrect) problem inherent in LLMs.
- Augments prompt with enterprise specific content to produce better responses.
- Avoids exceeding LLM token limits by using most relevant content.
Keyword search
Keywords match with the terms people search for when looking for products, services, or general information (e.g., Google search). Simplest form of search is based on exact matches of the user provided keywords in the database or index. It evaluates documents based on the presence and frequency of the query term. Example : BM25 algo
Semantic search
Through this the LLMs can understand the context and meaning (rather than keywords) behind the user input leading to more accurate responses.
The two ways you can leverage semantic search are dense retrieval and reranking.
- Dense retrieval: This enables the retrieval system to understand, and match based on the contextual similarities between queries and documents.
- Reranking: This improves the quality and relevance of results generated during the initial retrieval process and reorders them.
Using the OCI generative AI service you can access pretrained models or create and host your own fine-tuned custom models based on your own data on dedicated clusters. Langchain is a Opensource framework for developing applications powered by language models. LangChain offers multitude of components to build LLM based applications, including an integration with OCI generative AI service, vector databases, document loaders, and many others.
Further Reading :


Leave a Reply